Samenvatting van het artikel
Alleen toegang als abonnee van maurice.nl of AI-lid Log hier in, als u toegangsinfo heeft: Email Wachtwoord Onthoud me Wachtwoord vergeten
Preview:
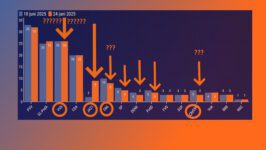
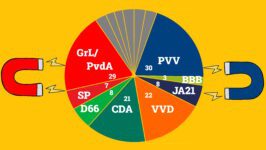
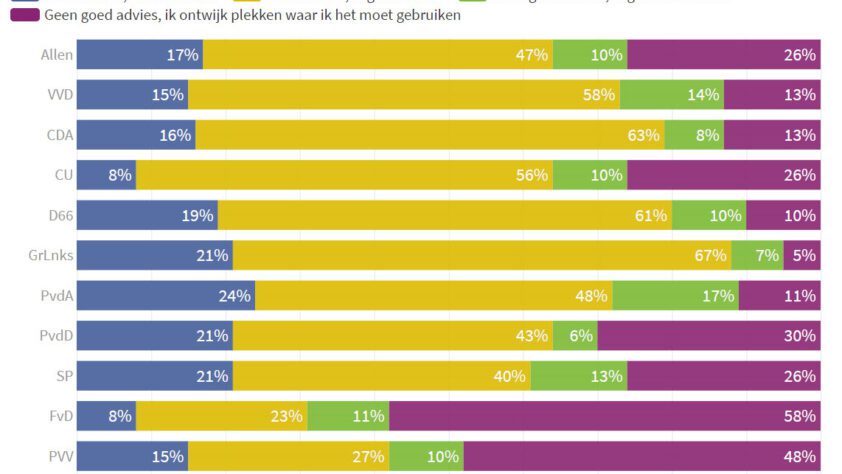
Onderzoek over mondkapjes en angst om besmet te worden Via Peil.nl is dit weekend o.a. dit vastgesteld: Dit is de reactie van de ondervraagde op het dwingend advies van de regering inzake mondbescherming in openbare binnenruimtes: (afbeelding) 64% van de Nederlanders vindt het advies v...